Introducing Vesper - HTTP Framework for Unix Shell
Technology is moving fast. The world has changed a lot since the 70ies. But one thing is still around: Unix shell. The bourne shell was initially released in 1977 and bash saw the light of the world in 1989. Why is the shell still around? And should we handle HTTP requests with the shell?
Background: Is the shell dead?
Before we talk about vesper, let’s think about the shell itself. In the 90ies, Microsoft pushed the desktop experience for servers and it was powerful. Without all the background knowledge, users could set up an Active Directory, NFS and manage a lot of users. This was also possible with Linux but just way more complicated. But at some point, Windows servers became less popular. It’s difficult to answer why this happened, but I guess that the automation of tasks was just too difficult. Tools like Puppet & Chef saw the world and made the deployment of servers so much easier. At some point, users could express powerful things in a UNIX shell which leads to the development of PowerShell (which object-based input/output is super neat) and ultimately Windows Subsystem for Linux. The shell is also ported to the browser with Google Cloud Shell and Azure Cloud Shell. Shell automation is so powerful, that developers automate all kinds of small tasks in shell scripts. I know administrators that automated full server rollouts with shell scripts. If you build your cloud AMI with Packer, you most-likely also automate the installation with shell scripts. Therefore, I have to conclude that the shell has never been more alive.
Shell-based microservices
For my local development, I’ve written a shell script that uploads a file to aws s3. Their CLI makes it very easy:
# do x and then upload
aws s3 cp --acl public-read file.zip s3://bucketNow, if I want to run the script as part of the CI job, I can just execute the shell script there. But to do that, the CI needs access to internal systems. What if the CI would need to call the script that is not accessible in the CI repository?
I ended up writing a small service in GO that does exactly the same as the bash script I’ve already written. While it worked perfectly, I was asking myself why I spent the 2 hours on that implementation? Why is it not possible to call shell scripts remotely?
Experiment: Shell web server in 5-lines of code
I started playing with the thought of simple shell web server and played with netcat:
ncat -lk -p 8080 --sh-exec '
echo "HTTP/1.0 200 Ok";
echo "Content-Type: text/plain;charset=UTF-8";
echo;
echo "Hello World";
echo;'Wow. This already worked. As the next step, I want to ship a pdf document that is viewable in a browser:
ncat -lk -p 8080 --sh-exec '
echo "HTTP/1.0 200 Ok" > /dev/stdout;
echo "Content-Type: application/pdf" > /dev/stdout;
echo "Content-Length: 8189970" > /dev/stdout;
echo "" > /dev/stdout;
cat doc.pdf > /dev/stdout'The script has still challenges: fixed file size and non-compliant stdout pipes. /dev/stdout & /dev/stderr is not posix compliant, therefore we replace /dev/stdout with >&1 and /dev/stderr with >&2.
For the next iteration, lets also include automatic mime detection and dynamtic determination of the file size:
export FILENAME=doc.pdf
ncat -lk -p 8080 --sh-exec '
echo "HTTP/1.0 200 Ok" >&1;
echo "Content-Type: $(file --mime-type -b $FILENAME)" >&1;
echo "Content-Length: $(stat -f%z $FILENAME)" >&1;
echo "" >&1;
cat $FILENAME >&1'Since we solved all the piping, I wanted to tackle the json output to build a micro service in bash:
ncat -lk -p 8080 --sh-exec '
echo "HTTP/1.0 200 Ok" >&1;
echo "Content-Type: application/json" >&1;
echo "" >&1;
BUCKET_NAME="blob_bucket";
OBJECT_NAME="blob_object";
JSON_FMT="{\"bucketname\":\"%s\", \"objectname\":\"%s\"}\n";
printf "$JSON_FMT" "$BUCKET_NAME" "$OBJECT_NAME"'Vesper - HTTP Framework for Unix Shell
Since the examples proofed that it is possible to return all kinds of data via bash by using existing shell capabilities, I wanted to write a small layer of abstraction. The abstraction layer is really small though.
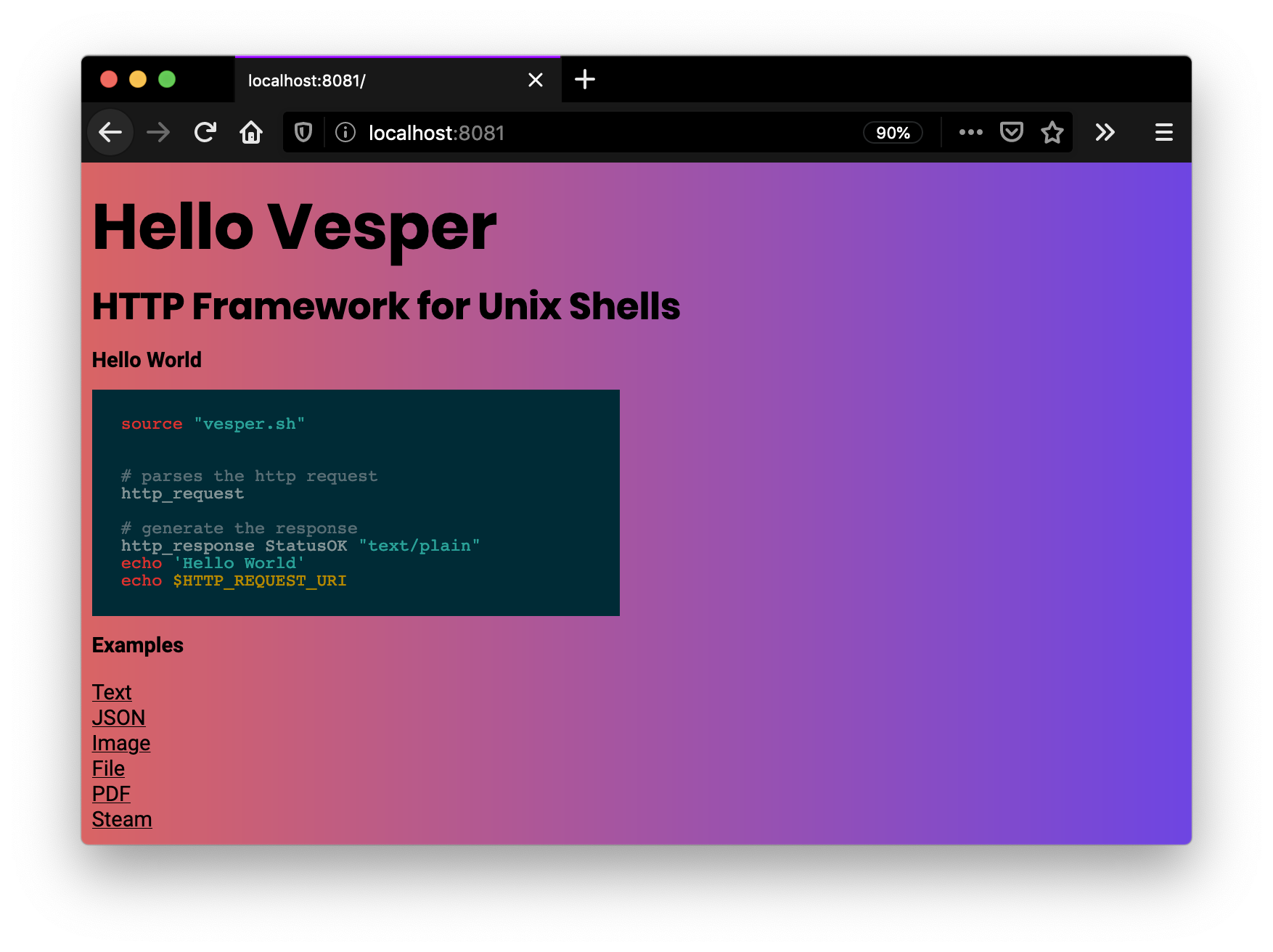
The helloworld.sh illustrates the basic output of the text:
source "vesper.sh"
# parses the HTTP request
http_request
# generate the HTTP response
http_response StatusOK "text/plain"
echo 'Hello World'
echo $HTTP_REQUEST_URIWith vesper you can even dynamically generate images and return them image.sh:
source "vesper.sh"
http_response StatusOK "image/jpeg"
echo "James Bond" | convert -font Arial -pointsize 72 -fill white -background black text:- -trim png:- >&1And it is also super easy to return a file stream:
source "vesper.sh"
http_response StatusOK "application/pdf"
wkhtmltopdf --quiet "http://tiswww.case.edu/php/chet/bash/bashtop.html" - >&1Building a router
Now, its time to compose a router, that can handle multiple routes:
# parse the HTTP request header
http_request
if [[ "$HTTP_REQUEST_URI" =~ "pdf" ]]; then
handle_pdf
exit 0
fi
if [[ "$HTTP_REQUEST_URI" =~ "json" ]]; then
handle_json
exit 0
fi
if [[ "$HTTP_REQUEST_URI" =~ "image" ]]; then
handle_image
exit 0
fi
if [ "$HTTP_REQUEST_URI" == "/" ]; then
http_response StatusOK "text/plain"
echo "Hello Vesper"
exit 0
fi
# default response
fail 400 "The route ${HTTP_REQUEST_URI} does not exist"To start the server, just run:
ncat -lk -p 8080 --sh-exec ./router.sh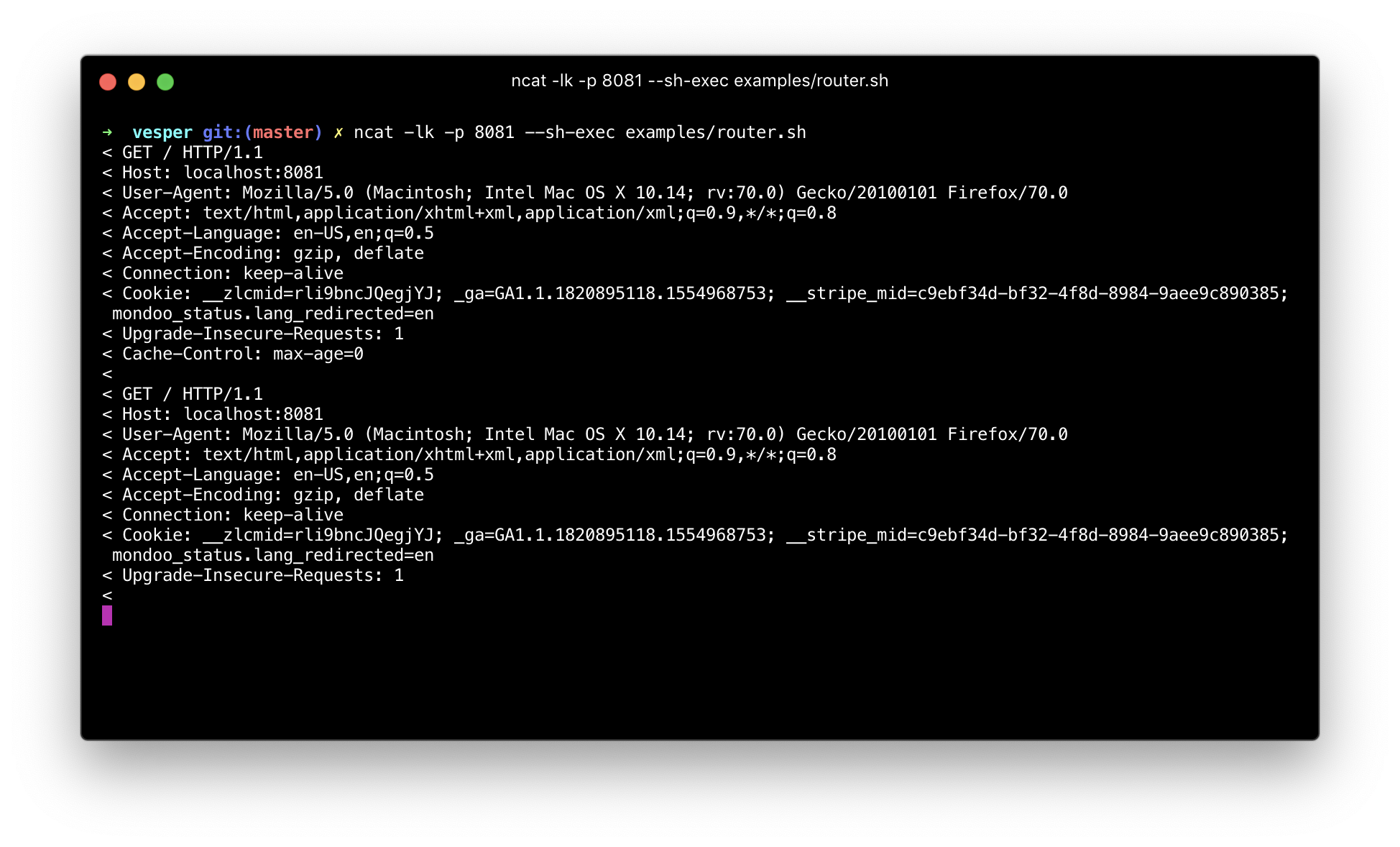
The full experiment is available on github.com/chris-rock/vesper. You can play with all experients there.
Conclusion
Although I built it for fun over the weekend, I am still not convinced if this is a good idea or not. It has some pros by being able to reuse existing scripts. From a security perspective, I think this is not a good idea at all. Just alone the missing input param validation is crying for privilege escalations. I’d like to hear your opinion via Reddit, Twitter or Github